The increase in data production and collection across multiple sectors has driven the adoption of specialized languages and tools for analyzing and extracting value from this information. The exponential growth in data generation has created a demand for resources that not only allow users to manipulate data, but also visualize, document, and communicate insights efficiently.
In this context, Python has emerged as one of the most widely used tools among data analysts and data scientists. Its ease of use, combined with a vast array of specialized libraries, makes it a natural choice for those seeking productivity and clarity in analytical workflows. The most popular types of notebooks are:
- Jupyter Notebook: enables code execution in cells with immediate feedback, supports multiple languages through kernels (such as Python, R, and Julia), and provides visualizations in charts, tables, and formats like HTML, LaTeX, and SVG. It is ideal for rapid prototyping and integrated documentation, thanks to its simple and interactive interface;
- JupyterLab: offers an integrated development environment (IDE) with support for multiple files and formats, including notebooks, scripts, and visualizations. It features a customizable interface and supports a variety of extensions that add extra functionality. It also enables multiple users to collaborate simultaneously;
- Google Colab: is a cloud-based, allowing access to GPUs and TPUs at no cost, making it easy to share and collaborate on notebooks via Google Drive. No local installation or configuration is required;
- Kaggle Kernels: support developing, sharing, and running code directly in the browser, offering free compute resources such as access to CPUs, GPUs, and TPUs. This notebook model is focused on data science and machine learning, with seamless integration into the Kaggle platform for competitions and datasets;
Additionally, Python’s advantages for data analysis are strongly supported by its ecosystem of libraries:
- Pandas: for manipulating and analyzing tabular data;
- NumPy: for mathematical operations and vectorization;
- Matplotlib and Seaborn: for creating static and interactive data visualizations;
- Scikit-learn: for machine learning and predictive modeling.
Database structures: from extraction to interpretation
Leveraging Python code enables direct connections to SQL (Structured Query Language) databases—including PostgreSQL, MySQL, and SQLite—by utilizing libraries such as sqlite3, SQLAlchemy, PyMySQL, among others. These libraries streamline access to relational databases and simplify the manipulation of their data, making it possible to seamlessly integrate Python code with the database.
This empowers analysts to run queries directly within their Notebooks, extract large volumes of data, and transform them into data structures like Pandas DataFrames for analysis, visualization, and subsequent modeling. This workflow facilitates a centralized process, from data extraction to interpretation, enhancing reproducibility and collaboration across teams.
Databases are essential for storing and retrieving vast amounts of industrial data. The chosen architecture—whether relational, document-oriented, time series, or data warehouse—directly impacts analytical efficiency:
- Relational databases like PostgreSQL and MySQL are widely adopted for data with a strong schema and relational integrity;
- NoSQL databases such as MongoDB and Cassandra are recommended for semi-structured or high-velocity data;
- InfluxDB is specialized for time series workloads, making it ideal for continuous sensor data ingestion.
Handling large-scale datasets requires query optimization techniques. Indexing accelerates searches on specific columns, partitioning breaks up massive tables into smaller, more manageable segments, and query planning enables the database engine to determine the most efficient execution path for operations.
Additionally, columnar storage formats like Parquet and ORC deliver performance benefits for selective column reads in large-scale analytical workloads. Collectively, these strategies ensure that even systems handling billions of records can query and process data efficiently.
Data preparation and modeling using Python for industrial environments
In industrial environments, the quality of data analysis relies heavily on effective data preparation. Data cleansing involves addressing inconsistencies, handling missing or duplicate records, standardizing formats, and identifying outliers that could skew results.
Data transformation includes modifying the structure or representation of data to facilitate analysis—for example, normalizing variables, creating categorical features, or performing time-based aggregations. Python, through libraries such as Pandas, Dask, and PySpark, provides robust tools to efficiently execute these steps, even with large-scale datasets.
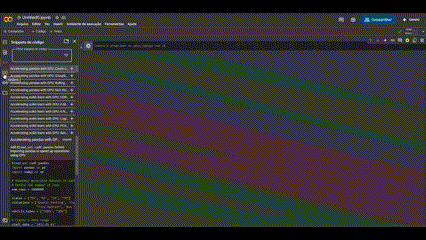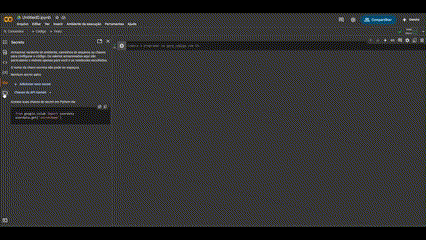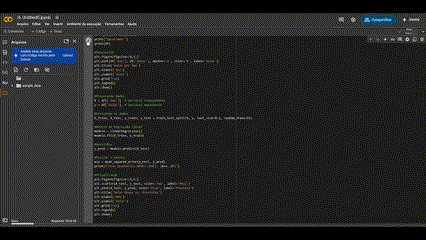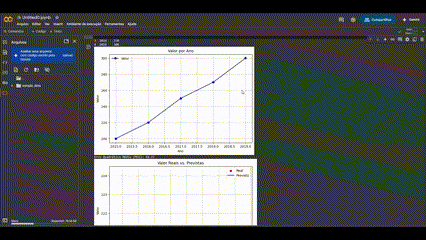
After preparation, data modeling enables the extraction of predictive or descriptive insights. In industrial applications, this can mean forecasting equipment failures, optimizing processes, or detecting anomalies. The use of Notebooks allows the entire process of preparation, transformation, and modeling to be documented in a single, interactive, and reproducible environment. This supports both traceability and collaboration between data teams and industrial process experts.
The adoption of Python in manufacturing environments has grown exponentially alongside the rise of industrial digitalization. The massive data collection from machine and equipment sensors—known as IoT—generates significant volumes of real-time information that require timely analysis. Python, when used in interactive Notebooks, enables agile exploration and analysis of this data, supporting initiatives such as predictive maintenance, process optimization, and quality control.
Libraries like Pandas for data manipulation, Seaborn and Plotly for data visualization, and Scikit-Learn for machine learning empower multidisciplinary teams to quickly interpret operational data and turn insights into actionable strategies. Additionally, the use of Notebooks fosters collaboration between data analysts and process engineers, promoting shorter innovation cycles and continuous improvement.
Implementing Data Analysis Using Python in a Beverage Industry
Manufacturing environments generate large volumes of data due to the number of machines operating simultaneously. Sensors are responsible for collecting data such as temperature, pressure, speed, and energy consumption. As a practical example, during the bottle-filling stage on a soft drink production line, sensors installed on the machines monitor several critical variables, including:
- fill rate;
- Unit count per minute;
- Liquid temperature;
- Internal reservoir pressure.
The labeling stage is crucial in preparing data for supervised machine learning models, as it involves assigning categories or tags to raw data based on defined criteria. In industrial environments, where sensors continuously generate data, automating this process becomes essential to ensure speed and scalability. Python offers libraries such as Pandas for data manipulation, Scikit-learn for classical machine learning, and frameworks like TensorFlow and PyTorch for deep learning, enabling the implementation of filtering, classification, and automated labeling algorithms.
For example, clustering or supervised classification algorithms can be used to detect anomalous patterns in temperature, vibration, or pressure measurements. Once these data points are automatically labeled, they can be organized into structured databases, making subsequent analysis more efficient.
For industrial data analytics to be effective, it is critical that professionals involved have in-depth knowledge of the business and operational processes. This expertise ensures that collected data is interpreted within their real-world context, avoiding misinterpretation and leading to actionable insights.
For instance, understanding how a production line operates makes it possible to identify which variables should be monitored, distinguish between normal and abnormal patterns, and pinpoint the most strategic performance indicators for the business. Additionally, domain knowledge is key to creating visualizations that clearly and objectively communicate analysis results, supporting data-driven decision-making.
Learn more about ST-One.