El auge en la producción y recolección de datos en diversos sectores ha impulsado la adopción de lenguajes y herramientas especializadas para analizar y extraer valor de esta información. El crecimiento exponencial en la generación de datos ha provocado una demanda de recursos que no solo permitan manipular datos, sino también visualizarlos, documentarlos y comunicar hallazgos de manera eficiente.
En este contexto, Python se ha posicionado como una de las herramientas más utilizadas entre analistas y científicos de datos. Su facilidad de uso, combinada con una amplia gama de bibliotecasespecializadas, lo convierte en la elección natural para quienes buscan productividad y claridad en sus flujos de trabajo analíticos. Los tipos más populares de notebooks son:
- Jupyter Notebook: permite ejecutar código en celdas con retroalimentación inmediata, soporta múltiples lenguajes mediante kernels (como Python, R y Julia), y ofrece visualizaciones en gráficos, tablas y formatos como HTML, LaTeX y SVG. Es ideal para la creación rápida de prototipos y documentación integrada, gracias a su interfaz sencilla e interactiva;
- JupyterLab: provee un entorno de desarrollo integrado (IDE) con soporte para múltiples archivos y formatos, incluyendo notebooks, scripts y visualizaciones. Cuenta con una interfaz personalizable y soporta diversas extensiones que añaden funcionalidades extra. También proporciona la colaboración simultánea entre varios usuarios;
- Google Colab: basado en la nube, permite acceso a GPUs y TPUs sin costo, facilitando el compartir y colaborar en notebooks mediante Google Drive. No requiere instalación ni configuración local;
- Kaggle Kernels: permite desarrollar, compartir y ejecutar código directamente en el navegador, ofreciendo recursos de cómputo gratuitos como acceso a CPUs, GPUs y TPUs. Este modelo de notebook está enfocado en ciencia de datos y aprendizaje automático, con integración directa a la plataforma de Kaggle para competencias y conjuntos de datos.
Además, las ventajas de Python para el análisis de datos están fuertemente respaldadas por su ecosistema de librerías, entre las que destacan:
- Pandas: para manipulación y análisis de datos tabulares;
- NumPy: para operaciones matemáticas y vectorización;
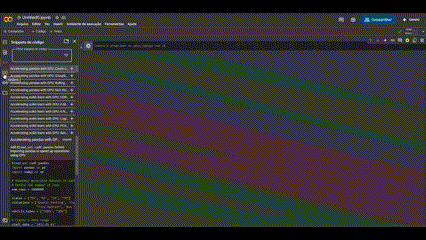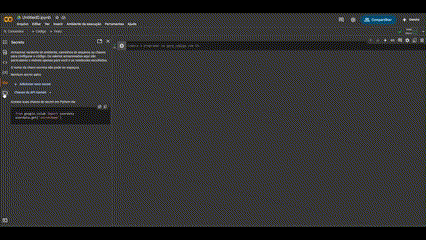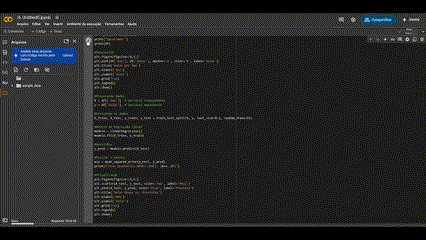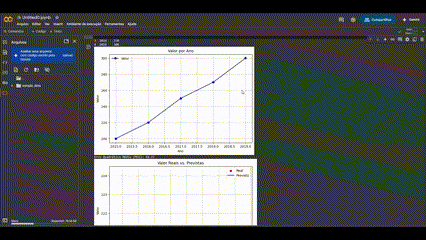
- Matplotlib y Seaborn: para crear visualizaciones de datos, tanto estáticas como interactivas;
- Scikit-learn: para aprendizaje automático y modelos predictivos.
Estructuras de bases de datos: de la extracción a la interpretación
Aprovechar código en Python permite conexiones directas a bases de datos SQL (Structured Query Language), incluidas PostgreSQL, MySQL y SQLite, mediante el uso de librerías como sqlite3, SQLAlchemy, PyMySQL, entre otras. Estas librerías facilitan el acceso y la manipulación de datos almacenados en bases de datos relacionales, permitiendo una integración fluida con Python.
Esto permite a los analistas la capacidad de ejecutar consultas directamente desde sus Notebooks, extraer grandes volúmenes de datos y transformarlos en estructuras como DataFrames de Pandas. Estos datos pueden luego ser analizados, visualizados y modelados. Este flujo de trabajo facilita un proceso centralizado, desde la extracción de datos hasta la interpretación, mejorando la reproducibilidad y la colaboración entre equipos.
Las bases de datos son esenciales para almacenar y recuperar grandes cantidades de datos industriales. La arquitectura seleccionada—ya sea relacional, orientada a documentos, de series de tiempo o data warehouse—impacta directamente la eficiencia analítica:
- Las bases de datos relacionales como PostgreSQL y MySQL son ampliamente adoptadas para datos con esquemas sólidos e integridad relacional;
- Las bases de datos NoSQL como MongoDB y Cassandra se recomiendan para datos semiestructurados o de alta velocidad;
- InfluxDB está especializada en cargas de trabajo de series de tiempo, por lo que es ideal para la ingesta continua de datos de sensores.
El manejo de datasets a gran escala requiere técnicas de optimización de consultas. El uso de índices acelera las búsquedas en columnas específicas, la partición divide tablas masivas en segmentos más manejables, y la planificación de consultas permite al motor de la base de datos determinar la ruta de ejecución más eficiente para las operaciones.
Además, los formatos de almacenamiento por columnas como Parquet y ORC ofrecen beneficios de rendimiento para lecturas selectivas de columnas en cargas de trabajo analíticas a gran escala. En conjunto, estas estrategias aseguran que incluso los sistemas que procesan miles de millones de registros puedan consultar y procesar datos de manera eficiente.
Preparación y modelado de datos en Python para entornos industriales
En los entornos industriales, la calidad del análisis depende en gran medida de la etapa inicial de la preparación de datos. La limpieza de datos implica abordar inconsistencias, eliminar registros faltantes o duplicados, estandarizar formatos e identificar valores atípicos que podrían sesgar los resultados.
La transformación de datos implica modificar la estructura o representación de la información para facilitar su análisis—por ejemplo, normalizando variables, creando variables categóricas o realizando agregaciones temporales. Python, a través de librerías como Pandas, Dask y PySpark, ofrece herramientas robustas para ejecutar estos pasos de manera eficiente, incluso con conjuntos de datos a gran escala.
Tras la preparación, el modelado de datos permite extraer insights predictivos o descriptivos. En aplicaciones industriales, esto puede significar anticipar fallas en equipos, optimizar procesos o detectar anomalías. El uso de Notebooks permite documentar todo el proceso de preparación, transformación y modelado en un solo entorno interactivo y reproducible. Esto respalda tanto la trazabilidad como la colaboración entre los equipos de datos y los expertos en procesos industriales.
La adopción de Python en entornos industriales ha crecido exponencialmente junto con el auge de la digitalización industrial. La captura masiva de datos provenientes de sensores de maquinaria y equipos—lo que se conoce como IoT—genera volúmenes significativos de información en tiempo real que requieren ser analizados de manera ágil. Python, al emplearse en Notebooks interactivos, posibilita la exploración y el análisis ágil de estos datos, apoyando iniciativas como mantenimiento predictivo, optimización de procesos y control de calidad.
Librerías como Pandas para manipulación de datos, Seaborn y Plotly para la visualización, y Scikit-Learn para el aprendizaje automático, permiten a equipos multidisciplinarios interpretar rápidamente los datos operativos y transformar los hallazgos en estrategias accionables. Además, el uso de Notebooks fomenta la colaboración entre analistas de datos e ingenieros de procesos, impulsando ciclos de innovación más cortos y una mejora continua.
Aplicación del análisis de datos con Python en una empresa de manufactura de bebidas
Las industrias manufactureras generan grandes volúmenes de datos debido a la cantidad de máquinas que operan simultáneamente. Los sensores se encargan de recolectar información como temperatura, presión, velocidad y consumo energético. Como ejemplo práctico, durante la etapa de llenado de botellas en una línea de producción de refrescos, los sensores instalados en las máquinas monitorean variables críticas, como:
- la tasa de llenado;
- Conteo de unidades por minuto;
- Temperatura del líquido;
- Presión interna del depósito.
La etapa de etiquetado es fundamental para preparar datos que serán utilizados en modelos de aprendizaje supervisado, ya que consiste en asignar categorías o etiquetas a los datos crudos según criterios definidos. En ambientes industriales, donde los sensores generan datos de forma continua, automatizar este proceso es esencial para garantizar velocidad y escalabilidad. Python ofrece librerías como Scikit-learn, Pandas y frameworks de deep learning como TensorFlow y PyTorch, que permiten implementar algoritmos para filtrado, clasificación y etiquetado automático de estos datos.
Por ejemplo, se pueden emplear algoritmos de clustering o clasificación supervisada para detectar patrones anómalos en mediciones de temperatura, vibración o presión. Una vez que estos datos son etiquetados de manera automática, pueden organizarse en bases de datos estructuradas, haciendo que el análisis posterior sea más eficiente.
Para que el análisis de datos industriales sea efectivo, es crucial que los profesionales involucrados tengan un conocimiento profundo del negocio y de los procesos operativos. Esta experiencia asegura que los datos recolectados se interpreten en su contexto real, evitando malas interpretaciones y generando insights accionables.
Por ejemplo, comprender cómo opera una línea de producción permite identificar qué variables se deben monitorear, distinguir entre patrones normales y anómalos, y definir los indicadores clave de desempeño más estratégicos para el negocio. Además, el conocimiento especializado es clave para crear visualizaciones que comuniquen los resultados del análisis de manera clara y objetiva, apoyando la toma de decisiones basada en datos.
Conoce más sobre ST-One.