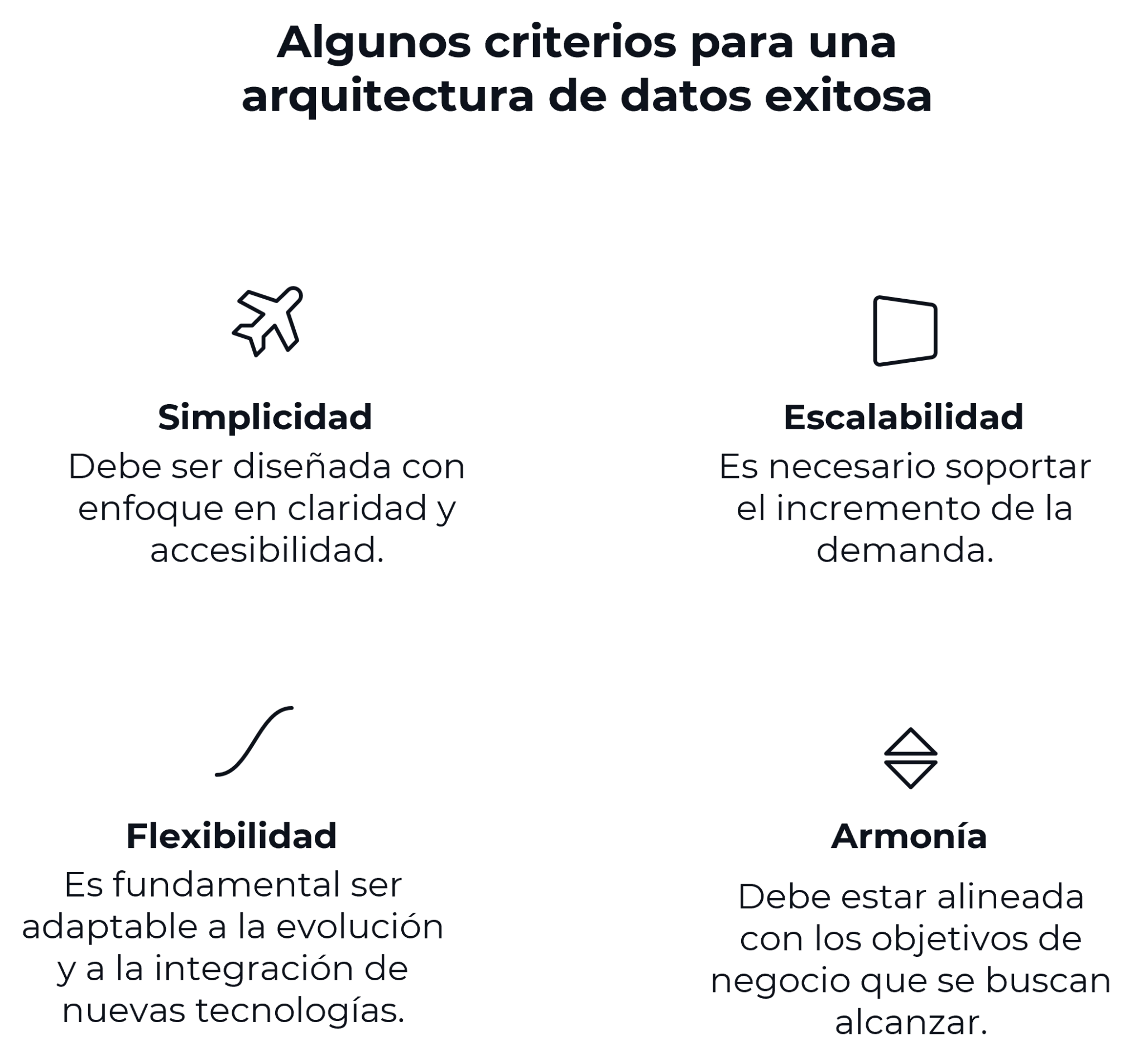
La arquitectura de datos industriales es un conjunto de tecnologías, procesos y estándares que organizan y gestionan todo tipo de variables generadas en entornos de manufactura. A partir de una arquitectura, es posible transformar datos en bruto provenientes de equipos y sensores en información.
Esta acción agrega valor a la operación, optimizando procesos y mejorando la calidad del producto. Para que una arquitectura sea robusta, escalable y satisfaga las necesidades específicas de cada tipo de manufactura, es necesario considerar los siguientes puntos:
- Fuente de datos;
- Volumen y velocidad (big data);
- Calidad de los datos;
- Escalabilidad y flexibilidad;
- Seguridad y gobernanza de datos;
- Integración de sistemas;
- Almacenamiento;
- Herramientas de análisis y visualización;
- Costo y mantenimiento.
Así, existe una lógica estratégica que puede seguirse para que esta implementación ocurra de manera cíclica y gradual:
- Planeación y descubrimiento: definición de la base del proyecto;
- Colección e integración de datos: construcción de canales para llevar los datos desde sus fuentes a un repositorio central;
- Procesamiento y almacenamiento: estructuración de los datos para que se vuelvan útiles;
- Análisis y consumo: extracción de valor de los datos;
- Gobernanza y evolución: garantía de longevidad y seguridad de la arquitectura.
Por ejemplo, en una industria de procesamiento animal de tamaño mediano, donde se producen de 5 a 10 toneladas diarias, cada etapa del proceso genera una gran cantidad de datos. En este contexto, una arquitectura de datos bien diseñada es fundamental para garantizar eficiencia operativa, rentabilidad, inocuidad alimentaria y cumplimiento de las regulaciones.
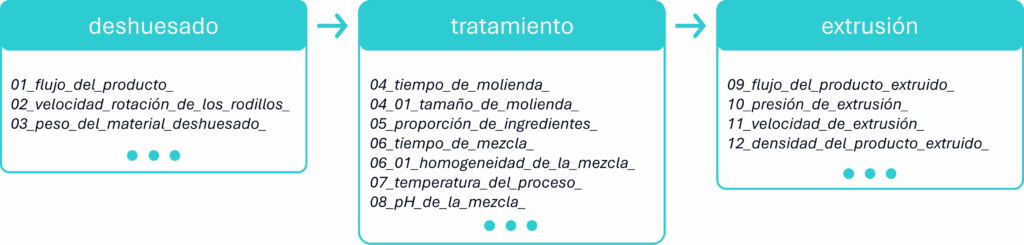
Con la complejidad de datos en cada etapa, este ejemplo ilustra la necesidad de una arquitectura de datos robusta. Sin embargo, el verdadero desafío es cómo manejar el gran volumen y la velocidad de estos datos. Para resolver esta cuestión, las aplicaciones de Edge Computing y Cloud Computing pueden funcionar como soluciones complementarias.
Edge y Cloud: estrategias de arquitectura para la industria
Para que una arquitectura de datos industrial sea realmente eficaz y cumpla con el objetivo de transformar datos en bruto en valor, es fundamental que esté sustentada por tecnologías que permitan el procesamiento eficiente de esta información.
Edge Computing y Cloud Computing son dos enfoques para el procesamiento de datos que funcionan de manera complementaria para optimizar las operaciones. La elección entre una u otra (o la combinación de ambas), depende directamente del tipo de aplicación, la necesidad de respuesta en tiempo real y el volumen de datos.
Al llevar el procesamiento de datos más cerca de la fuente donde se generan, las aplicaciones de Edge Computing, en lugar de depender de un servidor central, posibilitan respuestas en tiempo real. Por esta razón, esta tecnología se utiliza en mantenimiento predictivo, control de calidad en líneas de producción y automatización industrial.
En el contexto del post-procesamiento de carnes, por ejemplo, mantener la temperatura ambiental dentro de un rango establecido garantiza la calidad del alimento. Con monitoreo en tiempo real, cualquier variación se detecta rápidamente, permitiendo una acción inmediata antes de que la desviación cause daños al producto.
Por otro lado, las aplicaciones de Cloud Computing pueden emplearse en escenarios que involucran análisis complejos, almacenamiento a largo plazo y actividades que no requieren respuesta en tiempo real. Entre sus usos más comunes se encuentra el análisis de datos históricos, enfocado en la optimización de procesos, escalabilidad y flexibilidad en la asignación de recursos.
En el caso del monitoreo de temperatura en el post-procesamiento de carne, el historial de datos ayuda a identificar variaciones que puedan comprometer la calidad. Con esta información es posible tomar decisiones acertadas, como la descalificación de un lote completo, garantizando la inocuidad alimentaria y el cumplimiento de las normativas sanitarias.
La integración de estas aplicaciones conforma una arquitectura de nube híbrida, que se refiere a un entorno integrado que combina infraestructuras locales, nubes privadas, nubes públicas y soluciones de Edge Computing. Esta asociación forma una infraestructura de TI unificada y con capacidad de adaptación.
Diseñando datos: Data Lake y Data Warehouse para la industria
Una vez que el procesamiento y la infraestructura están establecidos, el siguiente paso fundamental para transformar los datos en valor es su almacenamiento y análisis estratégico. Para ello, las aproximaciones de Data Lake y Data Warehouse son esenciales.
La estructura física de un Data Lake combina almacenamiento escalable con motores de procesamiento distribuido, ideal para resguardar datos en bruto y no estructurados provenientes de múltiples fuentes, además de componentes como ingestión, catálogo, gobernanza y procesamiento.
La ingestión se realiza mediante pipelines que soportan tanto flujos continuos como cargas por lotes, garantizando flexibilidad en la captura de datos en tiempo real e históricos. Un sistema de catalogación organiza los metadatos, facilitando la exploración, trazabilidad y la aplicación de políticas de gobernanza.
El procesamiento es ejecutado por motores compatibles con múltiples paradigmas analíticos, como consultas SQL, análisis estadístico, aprendizaje automático y procesamiento distribuido. En la industria de procesamiento de carne, esto incluye:
- Datos de sensores de maquinaria: información sobre temperatura y presión de los equipos, que con frecuencia se genera a alta frecuencia;
- Datos de lotes rechazados: información detallada acerca de los lotes que son rechazados por el control de calidad;
- Datos de empaque y expedición: datos en bruto como material, peso, sellado y temperatura de almacenamiento.
Por su parte, el Data Warehouse está orientado a datos estructurados y depurados, con una infraestructura optimizada para análisis confiables y ágiles. Los datos pasan por procesos ETL, siendo limpiados y estandarizados antes de almacenarse en esquemas relacionales.
La ingestión se rige por reglas de negocio, con enfoque en la consistencia. El catálogo está integrado al modelo de datos, y el procesamiento se orienta a análisis estructurados, agregaciones y generación de indicadores, lo que permite consultas confiables y ágiles para análisis exploratorios:
- Histórico de producción: información procesada como el peso del material deshuesado, la cantidad de empaques producidos por hora y el número de lotes rechazados;
- Análisis de eficiencia: cálculos sobre la eficiencia de cada línea de producción;
- Control de calidad: datos estandarizados de control de calidad, como el peso de cada empaque y el pH del producto final.
El uso combinado de estos tipos de repositorios conforma un sistema de gestión de datos eficaz, brindando a la industria manufacturera la capacidad de definir estrategias basadas en datos tanto en tiempo real como a largo plazo, y optimizar la eficiencia y la calidad de sus procesos y productos.
Conoce el Espacio Data Circle, un lugar para quienes exploran soluciones innovadoras en la intersección entre datos, programación y procesos industriales.
Conoce más sobre ST-One.