O aumento na produção e coleta de dados em diversas áreas impulsionou a adoção de linguagens e ferramentas específicas para análise e extração de valor a partir dessas informações. O crescimento exponencial da produção de dados gerou a necessidade de recursos que permitam não apenas manipular, mas também visualizá-los, documentá-los e comunicá-los de maneira eficiente.
Nesse cenário, a linguagem Python ganha destaque como uma das ferramentas mais utilizadas por analistas e cientistas de dados. Sua facilidade, aliada a uma vasta gama de bibliotecas especializadas, faz dela uma escolha natural para quem busca produtividade e clareza no desenvolvimento de análises. Os tipos de notebooks mais conhecidos são:
- Jupyter Notebook: permite a execução de código em blocos com retorno imediato, suporte a múltiplas linguagens via kernels (como Python, R e Julia), além de visualizações em gráficos, tabelas e formatos como HTML, LaTeX e SVG. É ideal para prototipação ágil e documentação integrada, graças à sua interface simples e interativa;
- JupyterLab: possui um ambiente de desenvolvimento integrado (IDE), com suporte para múltiplos arquivos e formatos, como notebooks, scripts e visualizações. Contém uma interface personalizável e suporta uma variedade de extensões que adicionam funcionalidades extras. Também permite que múltiplos usuários trabalhem simultaneamente;
- Google Colab: é baseado na nuvem, permitindo acesso a GPUs e TPUs sem custo, o que facilita que os notebooks sejam compartilhados e colaborados através do Google Drive. Não requer instalação ou configuração local.
- Kaggle Kernels: permite desenvolvimento, compartilhamento e execução de código diretamente no navegador e possui recursos de computação gratuitos, como acesso a CPUs, GPUs e TPUs sem custo. Este modelo de Notebook é focado em ciência de dados e aprendizado de máquina, com integração com a plataforma Kaggle para competições e datasets.
Além disso, a vantagem da linguagem Python para a análise de dados também está presente em seu ecossistema de bibliotecas:
- Pandas: manipulação e análise de dados em estruturas tabulares;
- NumPy: operações matemáticas e vetorização;
- Matplotlib e Seaborn: criação de visualizações estáticas e interativas;
- Scikit-learn: machine learning e modelagem preditiva.
Preparação e modelagem de dados em Python para ambientes industriais
Em ambientes industriais, a qualidade da análise de dados depende fortemente da etapa inicial de preparação dos dados. A limpeza consiste em tratar inconsistências, remover dados ausentes ou duplicados, padronizar formatos e identificar outliers que possam distorcer os resultados.
A transformação de dados envolve modificar sua estrutura ou representação para facilitar a análise — por exemplo, normalizando variáveis, criando variáveis categóricas ou realizando agregações temporais. Python, por meio das bibliotecas Pandas, Dask e PySpark, oferece ferramentas robustas para executar essas etapas de forma eficiente, inclusive em grandes volumes de dados.
Após a preparação, a modelagem de dados permite extrair conhecimento preditivo ou . Em aplicações industriais, isso pode significar prever falhas em máquinas, otimizar processos ou detectar anomalias. O uso de Notebooks permite documentar todo o processo de preparação, transformação e modelagem em um único ambiente interativo e reproduzível. Isso contribui tanto para a rastreabilidade quanto para a colaboração entre equipes de dados e especialistas do processo industrial.
A aplicação de Python em ambientes de manufatura tem crescido exponencialmente com o avanço da digitalização industrial. A coleta massiva de dados por sensores em máquinas e equipamentos — conhecida como IoT — gera um volume significativo de informações que precisam ser analisadas em tempo real. A linguagem Python, quando utilizada em Notebooks interativos, permite a exploração e análise ágil desses dados, viabilizando iniciativas como manutenção preditiva, otimização de processos e controle de qualidade.
O uso de bibliotecas como Pandas para manipulação de dados, Seaborn e Plotly para visualização, e Scikit-Learn para aprendizado de máquina permite que equipes multidisciplinares interpretem rapidamente dados operacionais e transformem insights em ações concretas. Além disso, o uso de notebooks favorece a colaboração entre analistas de dados e engenheiros de processo, promovendo ciclos mais curtos de inovação e melhoria contínua.
Aplicação de análise de dados por linguagem Python em uma indústria de bebidas
Indústrias de manufatura geram grandes volumes de dados devido à quantidade de máquinas em operação. Os sensores têm a função de coletar dados como temperatura, pressão, velocidade e consumo de energia. Como exemplo prático, na etapa de enchimento de garrafas em uma linha de produção de refrigerantes, sensores instalados nas máquinas monitoram:
- Variáveis críticas como taxa de enchimento;
- Contagem de unidades por minuto;
- Temperatura do líquido;
- Pressão interna dos reservatórios.
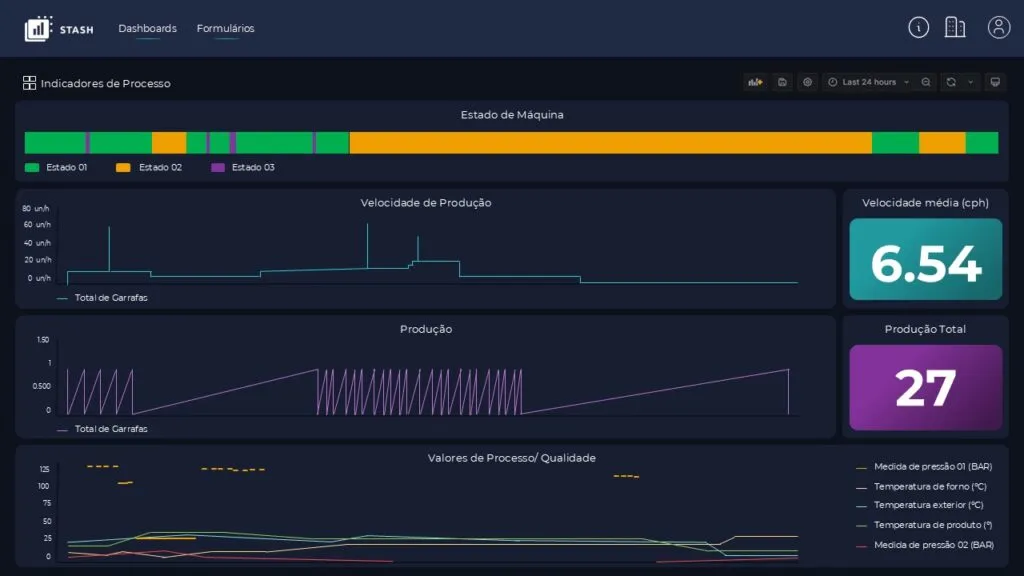
A etapa de rotulagem (labeling) é crucial na preparação de dados para modelos supervisionados de aprendizado de máquina, pois envolve a atribuição de categorias ou rótulos aos dados brutos com base em critérios definidos. Em ambientes industriais, onde sensores geram dados continuamente, a automação desse processo torna-se essencial para garantir agilidade e escalabilidade. Python oferece bibliotecas como Scikit-learn, Pandas e frameworks de deep learning (como TensorFlow e PyTorch) que permitem implementar algoritmos para filtragem, classificação e rotulagem automática desses dados.
Por exemplo, algoritmos de clustering ou classificação supervisionada podem ser usados para identificar padrões anômalos em medições de temperatura, vibração ou pressão. Esses dados, uma vez rotulados automaticamente, podem ser organizados em bancos de dados estruturados, facilitando sua análise posterior.
Para que a análise de dados industriais seja eficaz, é fundamental que os profissionais envolvidos possuam conhecimento aprofundado sobre o negócio e os processos operacionais. Esse entendimento permite que os dados coletados sejam interpretados dentro de seu contexto real, evitando interpretações equivocadas e conduzindo a insights relevantes.
Por exemplo, compreender o funcionamento de uma linha de produção permite identificar variáveis a serem monitoradas, padrões normais ou anômalos e indicadores de desempenho mais estratégicos para o negócio. Além disso, o conhecimento do domínio é essencial para a criação de visualizações que comuniquem de forma clara e objetiva os resultados das análises, orientando decisões baseadas em dados.
Saiba mais sobre a ST-One.