A arquitetura de dados industriais é um conjunto de tecnologias, processos e padrões que organizam e gerenciam todos os tipos de variáveis geradas em ambientes de manufatura. A partir de uma arquitetura, é possível transformar dados brutos de equipamentos e sensores em informações.
Essa ação agrega valor à operação, otimizando processos e melhorando a qualidade do produto. Para que uma arquitetura seja robusta, escalável e atenda às necessidades específicas de cada tipo de manufatura, é preciso considerar os seguintes pontos:
- Fonte de dados;
- Volume e velocidade (big data);
- Qualidade dos dados;
- Escalabilidade e flexibilidade;
- Segurança e governança de dados;
- Integração de sistemas;
- Armazenamento;
- Ferramentas de análise e visualização;
- Custo e manutenção.

Assim, existe uma lógica estratégica que pode ser seguida para que essa implementação ocorra de maneira cíclica e gradual:
- Planejamento e descoberta: definição da base do projeto;
- Coleta e integração de dados: construção de canais para trazer os dados de suas fontes para um local central;
- Processamento e armazenamento: estruturação de dados para se tornarem úteis;
- Análise e consumo: extração de valor dos dados;
- Governança e evolução: garantia de longevidade e segurança da arquitetura.
Por exemplo, em uma indústria de processamento animal de médio porte, onde são produzidas de 5 a 10 toneladas por dia, cada etapa do processo gera uma grande quantidade de dados. Nesse contexto, uma arquitetura de dados bem planejada é fundamental para garantir eficiência operacional, lucratividade, segurança alimentar e conformidade com as exigências regulatórias.
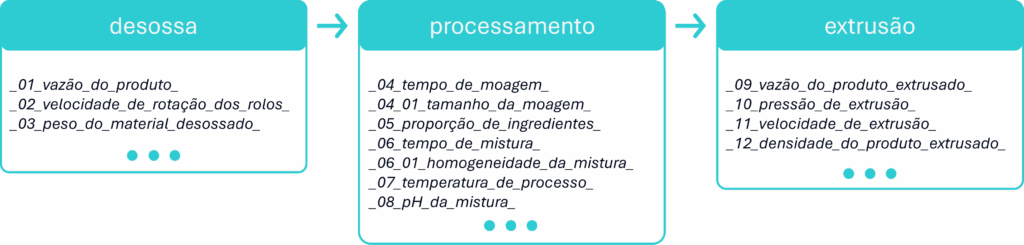
Com a complexidade de dados em cada etapa, esse exemplo ilustra a necessidade de uma arquitetura de dados robusta. No entanto, o desafio real é como lidar com o grande volume e a velocidade desses dados. Para resolver essa questão, as aplicações de Edge Computing e Cloud Computing podem funcionar como soluções complementares.
Edge e Cloud: estratégias de arquitetura para a indústria
Para que uma arquitetura de dados industrial seja realmente eficaz e cumpra o papel de transformar dados brutos em valor, é fundamental que ela seja sustentada por tecnologias que permitam o processamento eficiente dessas informações.
Edge Computing e Cloud Computing são duas abordagens para o processamento de dados que trabalham de forma complementar para otimizar as operações. A escolha entre uma ou outra (ou a combinação de ambas), depende diretamente do tipo de aplicação, da necessidade de tempo de resposta e do volume de dados.
Ao levar o processamento de dados para mais perto da fonte onde são gerados, as aplicações de Edge Computing, ao invés de depender de um servidor central, possibilitam respostas em tempo real. Por esse motivo, essa tecnologia é utilizada como manutenção preditiva, controle de qualidade em linhas de produção e automação.
No contexto do pós-processamento de carnes, por exemplo, manter a temperatura ambiente dentro de um padrão garante a qualidade do alimento. Com monitoramento em tempo real, qualquer variação é rapidamente detectada, permitindo uma ação imediata antes que o desvio cause danos ao produto.
Já as aplicações de Cloud Computing podem ser utilizadas em cenários que envolvem análises complexas, armazenamento de longo prazo e atividades que não demandam respostas em tempo real. Entre seus usos mais comuns estão a análise de dados históricos, com foco na otimização de processos, escalabilidade e flexibilidade na alocação de recursos.
No caso do monitoramento da temperatura no pós-processamento da carne, o histórico de dados ajuda a identificar variações que possam comprometer a qualidade. Com essas informações, é possível tomar decisões assertivas, como a desqualificação de um lote inteiro, garantindo a segurança alimentar e atendendo às exigências de fiscalização.
A junção dessas aplicações, forma uma arquitetura de nuvem híbrida, que se refere a um ambiente integrado que combina estruturas locais, nuvens privadas, nuvens públicas e soluções de Edge Computing. Essa associação forma uma infraestrutura de TI unificada e com capacidade para adaptação.
Projetando dados: Data Lake e Data Warehouse para indústria
Uma vez que o processamento e a infraestrutura estão estabelecidos, o próximo passo importante para transformar os dados em valor é o seu armazenamento e análise estratégica. Para isso, as abordagens de Data Lake e Data Warehouse são fundamentais.
A estrutura física de um Data Lake é a combinação de armazenamento escalável e de motores de processamento distribuído, ideal para armazenar dados brutos e não estruturados de várias fontes, além de componentes como ingestão, catálogo, governança e processamento.
A ingestão é realizada por pipelines que suportam tanto fluxos contínuos quanto cargas em lote, garantindo flexibilidade na captura de dados em tempo real e históricos. Um sistema de catalogação organiza os metadados, facilitando a descoberta, rastreabilidade e aplicação de políticas de governança.
O processamento é feito por motores compatíveis com múltiplos paradigmas analíticos, como consultas SQL, análise estatística, aprendizado de máquina e processamento distribuído. Na indústria de processamento de carne, isso inclui:
- Dados de sensores da máquina: informações de temperatura e pressão da máquina, que muitas vezes são geradas em alta frequência;
- Dados de lotes rejeitados: informações detalhadas sobre os lotes que são rejeitados pelo controle de qualidade;
- Dados de embalagem e expedição: dados brutos como os de material, peso, selagem e temperatura de armazenagem.
Já o Data Warehouse é voltado para dados estruturados e tratados, com infraestrutura otimizada para análise confiável e rápida. Os dados passam por processos de ETL, sendo limpos e padronizados antes do armazenamento em esquemas relacionais.
A ingestão é orientada por regras de negócio, com foco em consistência. O catálogo é integrado ao modelo de dados, e o processamento é voltado para análises estruturadas, agregações e geração de indicadores, o que permite consultas confiáveis e ágeis para análises exploratórias:
- Histórico de produção: informações processadas como o peso do material desossado, a quantidade de embalagens produzidas por hora e a quantidade de lotes rejeitados;
- Análise de eficiência: cálculos sobre a eficiência de cada linha de produção;
- Controle de qualidade: dados padronizados de controle de qualidade, como o peso de cada embalagem e o pH do produto final.
O uso combinado desses tipos de repositórios forma um sistema de gestão de dados eficaz, e oferece às indústrias de manufatura a capacidade de definir estratégias com base em dados, tanto em tempo real quanto a longo prazo, e otimizar a eficiência e a qualidade de seus processos e produtos.
Conheça o Espaço Data Circle, um lugar para quem explora soluções inovadoras para a interseção entre dados, programação e processos industriais.
Saiba mais sobre a ST-One.